
Obtén el máximo valor de la Dimensión Tiempo (tratamiento de Fechas y Horas) en un Data Warehouse y utilizala en tu solución de BI & Analytics. Incluyo scripts SQL que puedes utilizar.
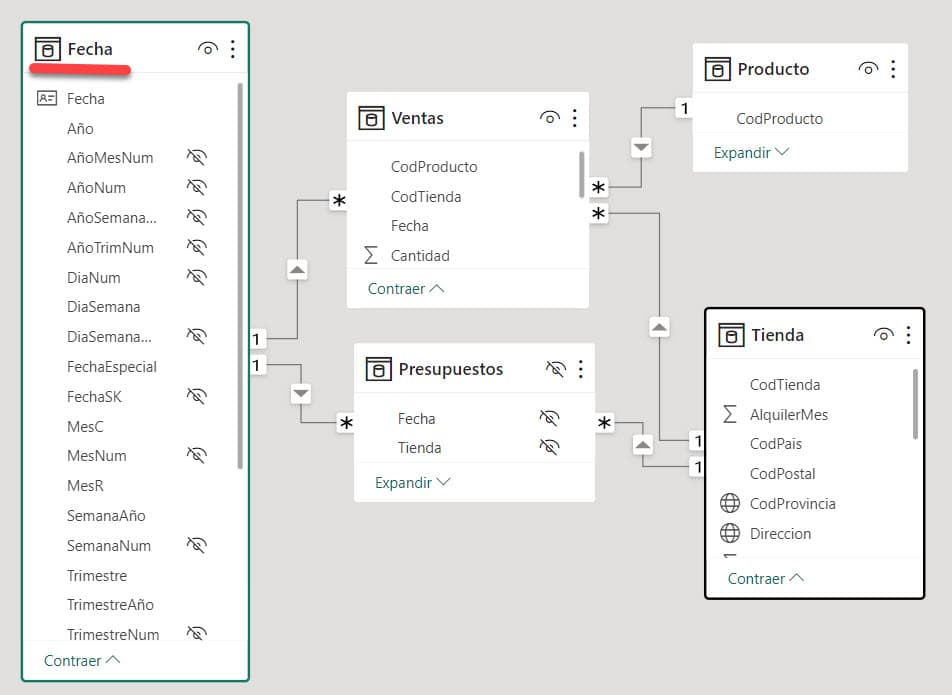
La Dimensión Tiempo suele encontrarse en la inmensa mayoría de nuestros proyectos y siempre estará presente en nuestro Data Warehouse.
Tratémosla como se merece y seremos recompensados en nuestros análisis de información.
En este artículo vamos a ver con todo detalle cómo diseñarla e implementarla.
Dimensiones Fecha y Hora para perfiles de IT y usuarios de Power BI y de otras herraminentas
Si tu perfil no es de TI y no estás familiarizado con el lenguaje SQL, también te interesa leer este artículo, ya que todo lo que aquí se explica debes conocerlo y aplicarlo, pide a tu departamento de TI que te genere estas tablas en una base de datos para que tú puedas utilizarlas.
Además, se puede aplicar creando estas tablas con Excel, ya que realmente partimos de un rango de fechas que se puede generar fácilmente arrastrando a partir de una fecha. Y prácticamente, lo que viene a continuación, se obtiene aplicando funciones de fecha (el mes, el día de la semana, etc.) e introduciendo datos.
Introducción
La dimensión Tiempo es una dimensión muy común, me atrevería a decir, que la más común en un Data Warehouse.
Esta dimensión suele estar relacionada con la mayoría de sus tablas de hechos, incluso es frecuente que lo haga por más de una columna. El motivo es obvio, hoy en día, cualquier análisis que vayamos a realizar, salvo raras excepciones, necesitará tener una perspectiva temporal disponible.
En mi experiencia en este mundo del Business Intelligence, rara vez me he encontrado casos en los que no hubiese una dimensión tiempo, por ejemplo, en un pequeño Data Mart orientado al análisis y segmentación de clientes. Eso sí, lo que no me he encontrado ha sido un Data Warehouse en el que no hubiese una dimensión Tiempo.
Si tan común es esta dimensión y aparece en cualquier diseño, ¿por qué en muchas ocasiones no se le da la importancia que merece y no conseguimos sacar de ella el máximo partido? Me he encontrado muchos diseños en los que esta dimensión se puede mejorar bastante, y principalmente, el motivo de ello, es que no se le ha dedicado el suficiente “tiempo” ???? a su diseño.
A continuación vamos a ir viendo los diferentes aspectos que debemos tener en cuenta a la hora de diseñarla:
- Diseñar las tablas y columnas que va a tener, y su contenido
- Elegir su granularidad
- Elegir el proceso de carga
- Decidir la frecuencia de carga
Incluyo también este video de la conferencia que impartí para PASS en español:
.
El tratamiento del tiempo, es un tema muy importante en cualquier solución de BI & Analytics, por ello, lo abordo en todas mis formaciones y mentorías. Incluso cuando es un curso básico orientado a usuarios. Considero fundamental difundirlo, ya que se utiliza mal o ni tan siquiera se utiliza, generando muchas dificultades a la hora de analizar la información.
Diseño de la dimensión Tiempo (Fechas y Horas)
A continuación se dan dos aproximaciones de diseño de las tablas que contendrán la información relativa al tiempo, de forma separada por fines didácticos, una para las fechas y otra para las horas, con una serie de columnas que basadas en nuestra experiencia, son un buen punto de partida como diseño de nuestra Dimensión Tiempo.
Es el momento de decidir qué columnas van a formar parte de cada una de estas tablas, con el fin de más adelante poder responder de la forma que espera el usuario a cualquier pregunta relativa al tiempo. No nos debe importar que ha-ya una gran cantidad de columnas, aunque en principio esto pueda sorprender a algún lector, he de decir, que no es extraño encontrarnos con tablas para el tratamiento del tiempo con varias decenas de columnas, e incluso centenares.
Entre ellas podemos tener columnas para gestionar diferentes calendarios (por campañas o temporadas, fiscales u otros), para el uso de múltiples idiomas, para representar un mismo dato de diferente forma de visualización, por ejemplo, relativo al trimestre podremos tener varias columnas, con formatos de valores como ‘T1’, ‘Trim 1’, ‘2009-T1’, ‘Q1/2009’, ‘Q1’, ‘Quarter 1’, etc. (esto es extrapolable al resto de datos).
En el código que veremos a continuación se incluyen algunas columnas habituales y el formato en el que se almacenará la información en ellas. Por su-puesto, que todo esto hay que contrastarlo con el usuario, incluir todas las columnas que estimemos oportunas, y que en ellas el contenido sea tal y como al usuario le interesa visualizarlo.
Nota: No dejes de leer los comentarios insertados a lo largo de los diversos bloques de código, donde también se incluyen alternativas a tener en cuenta, según el diseño que realicemos, para cada uno de nuestros proyectos. Se detallan los formatos en los que irá la información almacenada, y se hace referencia a alternativas según la versión de SQL Server utilizada.
Tabla de Dimensión Fecha
--create schema Dimension
CREATE TABLE Dimension.Fecha(
[DateKey] [int] NOT NULL, /* Format: AAAAMMDD */
[Date] [datetime] NOT NULL, /* Actual date */
[FullDate_Description] [nvarchar](100) NULL, /* Actual date description*/
[DayNumberOfWeek] [tinyint] NULL, /* 1 to 7 */
[DayNumberOfMonth] [tinyint] NULL, /* 1 to 31 */
[DayNumberOfYear] [smallint] NULL, /* 1 to 366 */
[WeekNumberOfYear] [tinyint] NULL, /* 1 to 53 */
[MonthNumberOfYear] [tinyint] NULL, /* 1 to 12 */
[CalendarQuarterOfYear] [tinyint] NULL, /* 1 to 4 */
[CalendarSemesterOfYear] [tinyint] NULL, /* 1 to 2 */
[CalendarYear] [char](4) NULL, /* Just the number */
[CalendarYearWeek] [nvarchar](25) NULL,/* Week Unique Identifier: Week + Year */
[CalendarYearMonth] [nvarchar](25) NULL,/* Month Unique Identifier: Month + Year */
[CalendarYearQuarter] [nvarchar](25) NULL,/* Quarter Unique Identifier: Quarter + Year */
[CalendarYearSemester] [nvarchar](25) NULL,/* Semester Unique Identifier: Semester + Year */
[CalendarYearWeek_Description] [nvarchar](25) NULL,/* Week Unique Descriptor: example - '2007-52' */
[CalendarYearMonth_Description] [nvarchar](25) NULL,/* Month Unique Descriptor: example - '2007-12' */
[CalendarYearQuarter_Description] [nvarchar](25) NULL,/* Quarter Unique Descriptor: example - 'Q2/2007' */
[CalendarYearSemester_Description] [nvarchar](25) NULL,/* Semester Unique Descriptor: example - 'H1.07' */
[CalendarYear_Description] [nvarchar](25) NULL,/* Calendar Year Descriptor: example - 'CY 2007' */
[EnglishDayNameOfWeek] [nvarchar](10) NULL,
[SpanishDayNameOfWeek] [nvarchar](10) NULL,
[CatalanDayNameOfWeek] [nvarchar](10) NULL,
[EnglishMonthName] [nvarchar](10) NULL, /* January to December */
[SpanishMonthName] [nvarchar](10) NULL, /* Enero a Diciembre */
[CatalanMonthName] [nvarchar](10) NULL /* Gener a Desembre */
--Agregar o quitar las columnas que estimemos
--oportunas en nuestro diseño
CONSTRAINT [PK_DimDate_DateKey] PRIMARY KEY CLUSTERED
([DateKey] ASC)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY],
CONSTRAINT [AK_DimDate_Date] UNIQUE NONCLUSTERED
([Date] ASC)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]T-SQL 1. Estructura de la tabla de dimensión Fecha
Tabla de dimensión Hora
--create schema Dimension
CREATE TABLE [Dimension].[Hora](
[IdHora] [int] NOT NULL,
--Se puede cambiar el tipo de datos si tenemos SQL Server 2008
[Tiempo] [datetime] NOT NULL,
[Hora] [tinyint] NOT NULL,
[Minuto] [tinyint] NOT NULL,
[Segundo] [tinyint] NOT NULL,
[AM] [char](2) NOT NULL,
[NombreHora] [char](2) NOT NULL,
[NombreHoraAM] [char](5) NOT NULL,
[NombreMinuto] [char](2) NOT NULL,
[NombreSegundo] [char](2) NOT NULL,
[HoraMinuto] [char](5) NOT NULL,
[HoraMinutoAM] [char](8) NOT NULL,
[HoraMinutoSegundo] [char](8) NOT NULL,
[HoraMinutoSegundoAM] [char](11) NOT NULL,
--Agregar o quitar las columnas que estimemos
--oportunas en nuestro diseño
CONSTRAINT [PK_Hora] PRIMARY KEY CLUSTERED
(
[IdHora] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GOT-SQL 2. Estructura de la tabla de dimensión Hora
** Quiero agradecer a Jordi Rambla, creador del script en el que me basé para construir estos.
Como has podido comprobar, hemos dejado nuestras tablas diseñadas para registrar un nivel de granularidad hasta el nivel de segundos (muy rara vez podríamos necesitar milisegundos, pero si se diese el caso también se podría con-templar). Independientemente de la granularidad que vayamos a utilizar, podemos dejar nuestras tablas diseñadas de forma que incluyan columnas que describan ese máximo nivel.
Elegir la granularidad de cada tabla
La granularidad de la dimensión tiempo puede ser variada según la tabla de hechos con la que se vaya a relacionar. En su diseño, deberemos tener en cuenta el máximo nivel que vayamos a necesitar y además tener columnas que nos permitan acceder a un nivel incluso menor del requerido en ese momento.
Imaginemos que tenemos en nuestro Data Warehouse tablas de hechos con la información de Presupuestos, Ventas y Producción. Los presupuestos los realizamos a nivel mensual, mientras en el análisis de Producción los requisitos nos indican que el máximo nivel de detalle que necesitaremos será el día. En cambio, en Ventas, necesitaremos saber hasta el detalle de la hora y el minuto en que se realizó cada operación. En este caso nuestra Dimensión Tiempo deberá tener información detallada hasta el nivel de minutos. Ello no impide que la estructura de mi tabla esté preparada para soportar una granularidad de segundos, y que con un simple cambio en el proceso de ETL que alimentada con dicha información, como veremos más adelante.
Elegir el proceso de carga
Una vez que tenemos diseñada nuestra tabla y estudiados los posibles niveles de granularidad que vamos a necesitar, debemos proceder a realizar un proceso ETL que permita alimentar estas tablas.
- Hay diversas formas de realizar el proceso para la carga de la Dimensión Tiempo, estas son algunas de las más comunes:
Realizarlo mediante T-SQL. Hacer un procedimiento almacenado que inserte una fila para una fecha. Luego se hace un bucle con T-SQL que recorra un rango de fechas seleccionado y que por cada una de estas fechas llame al procedimiento almacenado y la inserte - Realizarlo mediante Integration Services. Utilizaremos un bucle For Loop, en el que por cada fecha, llamaremos a un Data Flow en el que haremos los cálculos de las columnas derivadas que necesitemos para esa fecha e insertaremos la fila correspondiente a esa fecha
- Si eres un usuario que no tiene conocimientos de SQL, también la puedes crear con Excel
Otra cosa a tener en cuenta, es que dada la poca frecuencia con la que se suele ejecutar este proceso de carga, igual una vez al año o incluso nunca (casi nunca). Además, cuando ejecutemos estos procesos el número de filas afectadas no será muy grande. Esto hace que no sea muy significativo el método de carga utilizado, si es con Integration Services, si es con T-SQL, si usa cursores (aunque nunca lo recomendaría), etc.
Tenga en cuenta que lo visto anteriormente son simplemente aproximaciones, y podemos hacer sobre ellas las variaciones que estimemos oportunas. Podemos no utilizar procedimientos almacenados e incluir en el script todos los cálculos de columnas. Podemos utilizar una CTE en lugar de un bucle, o cualquier otra variante que estimemos oportuna.
Carga de la dimensión Tiempo basada en T-SQL
Veamos a continuación un ejemplo de carga basado en instrucciones T-SQL, que nos puede servir de base para la carga de nuestra dimensión tiempo, simplemente con añadir nuevos cálculos para las columnas que finalmente incluyamos en el diseño de nuestra dimensión. En este caso vamos a considerar que la máxima granularidad de nuestra tabla será el día, y vamos a llamar a dicha tabla Dimension.Fecha, partiendo inicialmente de muy pocas columnas, para más adelante, cuando hagamos su diseño definitivo, incorporar las columnas que estimemos oportunas.
Bucle de carga de Fechas
declare @StartDate datetime, @EndDate datetime
--Deberá ser la fecha más antigua de la que tengamos datos
set @StartDate = '19900101'
--Podemos bien dejar cargado un periodo muy amplio
--set @EndDate = '21001231'
--O bien, cargar los cinco próximos años completos
set @EndDate = cast(cast(year(getdate()) + 5 as char(4)) + '1231' as datetime)
while @StartDate <= @EndDate begin
exec InsertarFecha @StartDate
-- Podemos incrementar contador en años, meses o días
-- poniendo year, month o day en la función dateadd
set @StartDate = dateadd(day,1,@StartDate)
-- Lo más habitual es tener la granularidad día
endT-SQL 3. Bucle de carga de un rango de fechas, según granularidad indicada en el incremento de la variable @startdate
Procedimiento almacenado de carga de cada fila en la tabla Fecha
create procedure InsertarFecha
@CurrentDate datetime
as
insert into Dimension.Fecha([DateKey], [Date],
[DayNumberOfWeek], [EnglishDayNameOfWeek], [DayNumberOfMonth],
[DayNumberOfYear], [WeekNumberOfYear], [EnglishMonthName],
[MonthNumberOfYear], [CalendarQuarterOfYear], [CalendarYear],
[CalendarSemesterOfYear], [CalendarYearWeek], [CalendarYearMonth],
[CalendarYearQuarter], [CalendarYearSemester])
values(
(DATEPART(year , @CurrentDate) * 10000) + (DATEPART(month , @CurrentDate)*100)
+ DATEPART(day , @CurrentDate)
, @CurrentDate
, DATEPART(dw , @CurrentDate)
, DATENAME(dw, @CurrentDate)
, DATEPART(day , @CurrentDate)
, DATEPART(dayofyear , @CurrentDate)
, DATEPART(wk , @CurrentDate)
, DATENAME(month, @CurrentDate)
, DATEPART(month , @CurrentDate)
, DATEPART(quarter , @CurrentDate)
, DATEPART(year , @CurrentDate)
, CASE WHEN DATEPART(quarter , @CurrentDate) < 3 THEN 1
ELSE 2
END
, CAST(DATEPART(year , @CurrentDate) as char(4)) + '-'
+ RIGHT('0'+CAST(DATEPART(wk , @CurrentDate) AS varchar(2)),2)
, CAST(DATEPART(year , @CurrentDate) as char(4)) + '-'
+ RIGHT('0'+CAST(DATEPART(month , @CurrentDate) AS varchar(2)),2)
, CAST(DATEPART(year , @CurrentDate) as char(4)) + '-'
+ CAST(DATEPART(quarter , @CurrentDate) AS varchar(1))
, CAST(DATEPART(year , @CurrentDate) as char(4)) + '-'
+ CAST(CASE WHEN DATEPART(quarter , @CurrentDate) < 3 THEN 1
ELSE 2
END AS char(2))
)
GOT-SQL 4. Procedimiento almacenado que inserta una fila, calculando columnas derivadas elegidas, para la fecha recibida como parámetro
Actualizaciones para personalizar
A continuación mostramos la actualización de algunas columnas en función del idioma al que hacen referencia. Veremos que para algunas de ellas podemos aprovechar la propia configuración del lenguaje establecida en SQL Server, pero para otras debemos hacer nosotros esta tarea al no estar ese idioma disponible.
-- Update non-english language names
-- .. SPANISH / Spain / es-ES
SET LANGUAGE Spanish
UPDATE Dimension.Fecha
SET SpanishDayNameOfWeek = DATENAME(dw, [Date])
, SpanishMonthName = DATENAME(month, [Date])
WHERE Date >= @StartDate AND Date<= @EndDate -- Reset the language SET LANGUAGE us_english -- .. CATALAN UPDATE Dimension.Fecha SET CatalanDayNameOfWeek = CASE DayNumberOfWeek WHEN 2 THEN 'Dilluns' WHEN 3 THEN 'Dimarts' WHEN 4 THEN 'Dimecres' WHEN 5 THEN 'Dijous' WHEN 6 THEN 'Divendres' WHEN 7 THEN 'Dissabte' WHEN 1 THEN 'Diumenge' END, CatalanMonthName = CASE MonthNumberOfYear WHEN 1 THEN 'Gener' WHEN 2 THEN 'Febrer' WHEN 3 THEN 'Març' WHEN 4 THEN 'Abril' WHEN 5 THEN 'Maig' WHEN 6 THEN 'Juny' WHEN 7 THEN 'Juliol' WHEN 8 THEN 'Agost' WHEN 9 THEN 'Setembre' WHEN 10 THEN 'Octubre' WHEN 11 THEN 'Novembre' WHEN 12 THEN 'Desembre' END WHERE Date >= @StarDate AND Date<= @EndDate
T-SQL 5. Asignación según idioma a mostrar en esa columna
Nota: Por no hacer más largo el artículo, en estos bloques de código no se incluye todo el código necesario para todas las columnas de la tabla Dimiension.Fecha, hay cálculos de columnas que no están incluidos aquí. Dejamos al lector la labor de definir las columnas que estime oportunas y realizar los cálculos correspondientes.
Anteriormente sólo hemos llegado al nivel de granularidad de fecha, es decir, de una fila por cada día. Si queremos bajar a mayor detalle tendríamos que tener niveles de horas, minutos, segundos, o incluso menores. En este caso, lo que vamos a hacer es crear una tabla llamada Dimension.Hora en la que tendre-mos sólo las horas, sin las fechas, y veremos también su proceso de carga, basado en un bucle que recorre las veinticuatro horas del día y carga dicha tabla, llaman-do a un procedimiento almacenado que obtiene todas las columnas derivadas que estimemos oportunas.
Bucle de carga de hora
declare @Time datetime set @Time = convert(varchar,'12:00:00 AM',108) while @Time <= '11:59:59 PM' begin exec InsertarHora @Time -- Podemos incrementar contador en Horas, Minutos o Segundos -- poniendo hour, minute o second en la función dateadd set @Time = dateadd(hour,1,@Time) end
T-SQL 6. Bucle que carga las 24 horas del día, según granularidad indicada en el incremento de la variable @Time
Procedimiento almacenado de carga de cada fila en la tabla Hora
create procedure InsertarHora @Time datetime as declare @IdHora int, @Hora tinyint, @Minuto tinyint, @Segundo tinyint, @AM char(2), @NombreHora char(2), @NombreHoraAM char(5), @NombreMinuto char(2), @NombreSegundo char(2), @HoraMinuto char(5), @HoraMinutoAM char(8), @HoraMinutoSegundo char(8), @HoraMinutoSegundoAM char(11) --Calcular columnas mínimas necesarias set @Hora = datepart(hour, @Time) set @Minuto = datepart(minute, @Time) set @Segundo = datepart(second, @Time) set @IdHora = (@Hora*10000) + (@Minuto*100) + @Segundo --Se puede dejar tanto para granularidad minutos como --segundos, o bien --(@Hora*100) + @Minuto, para granularidad minutos, --pero luego no habría huecos para aumentar la --granularidad a segundos --@Hora, para granularidad horas, pero luego no habría -- huecos para aumentar la granularidad a minutos o segundos --Aquí se agregarán todos los cálculos en base a esa hora --que estimemos oportunos --Mostramos algunos de los formatos más habituales, --pero no su cálculo, sino que le asignamos un valor fijo --a modo de ejemplo set @AM = right(convert(varchar,@Time,109),2) -- AM/PM set @NombreHora = '00' -- HH con ceros por la izquierda set @NombreHoraAM = '12 AM' -- HH AM las 00 son las 12 AM set @NombreMinuto = '00' -- MM con ceros por la izquierda set @NombreSegundo = '00' -- SS con ceros por la izquierda set @HoraMinuto = '00:00' -- HH:MM con ceros por la izquierda set @HoraMinutoAM = '12:00 AM' -- HH:MM AM las 00:00 son las 12:00 AM set @HoraMinutoSegundo = convert(varchar, @Time, 108) -- HH:MM:SS set @HoraMinutoSegundoAM = '12:00:00 AM' -- HH:MM:SS AM las 00:00:00 son las 12:00:00 AM --Insertar fila insert into Dimension.Hora(IdHora, Tiempo, Hora, Minuto, Segundo, AM, NombreHora, NombreHoraAM, NombreMinuto, NombreSegundo, HoraMinuto, HoraMinutoAM, HoraMinutoSegundo, HoraMinutoSegundoAM) select @IdHora, @Time, @Hora, @Minuto, @Segundo, @AM, @NombreHora, @NombreHoraAM, @NombreMinuto, @NombreSegundo, @HoraMinuto, @HoraMinutoAM, @HoraMinutoSegundo, @HoraMinutoSegundoAM GO
T-SQL 7. Procedimiento almacenado que inserta una fila, calculando las columnas derivadas elegidas, para la hora recibida como parámetro
Nota: El procedimiento almacenado anterior no está terminado por completo, hay cálculos de columnas que no están realizados, y que graban un mismo valor para todas las filas a modo de ejemplo. Dejamos al lector la labor de definir las columnas que estime oportunas y realizar los cálculos correspondientes.
Por qué separar en dos tablas: dimension Fecha y dimension Hora
Como ha podido comprobar, hemos hecho un tratamiento del tiempo basado en dos tablas, por un lado el tratamiento de Fechas y por otro lado el tratamiento de Horas. Si no es su caso y necesita tener una sola tabla, con la granularidad que estime oportuna, bien puede adaptar el material anterior y cambiar el diseño para que el nivel de granularidad sea mayor y que todo gire en torno a una sola tabla, o bien, puede mantenerlo, y mediante una CROSS JOIN puede obtener el resultado de una sola tabla que incluya el producto cartesiano de ambas tablas.
select * --Puede seleccionar aquí las columnas que estime oportunas from Dimension.Fecha cross join Dimension.Hora
T-SQL 8. CROSS JOIN entre las tablas Fecha y Hora
Incluso podemos mejorar para crear la clave subrogada de la dimensión de forma inteligente, conteniendo la fecha y la hora.
select
cast(cast(Datekey as bigint)*1000000 + IdHora as bigint) IdTime
, * --Puede seleccionar aquí las columnas que estime oportunas
from Dimension.Fecha cross join dimension.Hora
order by DateKey, IdHora
T-SQL 9. CROSS JOIN y creación de la clave inteligente con fecha y hora, formato: AAAAMMDDhhmmss
Mi recomendación, es crear tablas separadas en el tratamiento del Tiempo, una para Fechas y otra para Horas. Queda más claro para el lector, es más fácil de gestionar y almacenamos un menor número de filas. Además, si alguien considera oportuno unirlas, puede hacerlo fácilmente con las cross join que acabo de mostrar. Deberá tener en cuenta que según la granularidad elegida, el número de filas de la tabla puede verse incrementado enormemente.
Elegir la frecuencia de carga de la dimensión Tiempo
La dimensión Tiempo es bastante atípica, en líneas generales, con respecto a la periodicidad de los procesos de carga, incluso puede que teóricamente nunca debamos volver a cargarla (al menos a lo largo de nuestra carrera profesional, cuidado que no nos ocurra como con el tratamiento del año 2000 :)). Como se indica en el Bloque de Código 3 si se indica un rango cuyo extremo inferior está en el año más antiguo del que tenemos datos en nuestra empresa y el superior en el año 2100, rara vez tendremos que cargar filas adicionales. En cambio hay otras alternativas que evitan tener todas esas filas cargadas sin necesidad durante largos periodos de tiempo. Por ejemplo se puede hacer una carga de los cinco siguientes años, y anualmente lanzar el proceso y agregar nuevas filas.
El único tema adicional que considero importante, es que en los procesos ETL de carga de hechos, habrá que tener en cuenta el tratamiento a realizar cuando entre un hecho con una fecha que no se encuentre almacenada en la Dimensión Tiempo. Podemos incluso hacer que el proceso cree una fila para esa fecha en la dimensión tiempo. Lo más habitual es que ese hecho arrastre algún error en el sistema transaccional, para lo cual debemos de alguna forma reflejar que se ha producido esa situación, bien grabando en alguna tabla de auditoría, bien llevando esas filas a otra tabla para revisión, o como estimemos oportuno, pero siempre dejando reflejada esa posible anomalía.
Consideraciones adicionales sobre la dimensión Tiempo
En lo visto anteriormente, hemos abordado de forma genérica el tratamiento de la dimensión tiempo, aunque en ciertos casos, habrá nuevas problemáticas que no estén cubiertas aquí. Vamos a citar una de las más habituales, pero no llegaremos a desarrollarla en este momento por el espacio que ocuparía. Lo dejamos pendiente para futuros artículos.
Es habitual que una empresa tenga diferentes sedes, y que estas estén en lugares geográficos distintos, en diversas ciudades a lo largo de la geografía. En ese caso, aunque una fecha es la misma en cualquier lugar del planeta, nos solemos encontrar con pequeñas variantes, como es el caso del tratamiento de los festivos, de periodos de cierre de producción en cada sede, o cualquier otro dato a tratar que pueda variar de un lugar a otro. Para estos casos, hemos visto una alternativa simple, que es tener una columna de festivos para cada lugar. Esta solución es rápida y válida en algunos casos, pero hay otros muchos que necesitan de una mayor flexibilidad, y que se puedan incorporar de forma automática nuevas sedes y por tanto nuevos calendarios, y no querremos estar añadiendo nuevas columnas a nuestra tabla y modificando nuestro proceso de ETL para que las alimente. En ese caso debemos cambiar la granularidad de nuestra tabla para tener una fecha por cada calendario que tengamos en nuestro sistema, así para un mismo día habrá tantas filas como calendarios tengamos definidos.
Le invito a realizar ciertas mejoras y adaptaciones, como utilizar el tipo de datos que mejor se adapte a sus necesidades, en base a los valores a almacenar. En lugar de utilizar los tipos de datos DateTime y SmallDateTime, que como bien sabe almacenan fecha y hora, hay disponibles otros tipos de datos que permiten almacenar sólo fechas, sólo horas, hacer tratamientos en base a zonas horarias y otras novedades que son aplicables en el diseño de la dimensión Tiempo.
Conclusiones
Hemos dado una visión general del tratamiento de la dimensión tiempo, recogiendo nuestras experiencias con ella y mostrando las problemáticas más habituales que nos hemos ido encontrando, así como la forma de resolverlas. Esperamos que este documento sirva como base a la hora de crear su propia dimensión Tiempo y adaptarla a sus necesidades, que evite el olvido de detalles importantes citados aquí y que le facilite un diseño completo y fácil de implementar en sus proyectos.
El buen uso de la Dimensión Tiempo (Fecha y Hora) te ayuda a evitar uno de los 3 errores más dañinos que cometen los analistas de datos.
Si quieres obtener los mejores resultados con Power BI, te invito a descargar esta guía:
Power BI: Los 3 errores más dañinos y cómo evitarlos

Tus dashboard e informes con Power BI serán mucho más óptimos. Tendrás soluciones profesionales.
Y evitarás frustraciones y soluciones ineficientes que tendrás que rediseñar y volver a construir.



2 comentarios en “La guia definitiva sobre la Dimension Tiempo en un Data Warehouse”
¡Buen día!
Muy bueno, este material. Estoy contenta y muy agradecida con el señor Salvador Ramos, por brindar sus conocimientos en la forma correcta, para el tratamiento de datos, relacionados con fechas. Estoy iniciándome en el estudio Power BI y sus artículos, incrementarán mi formación. Dios lo bendiga, @salvador_ramos
gran explicación